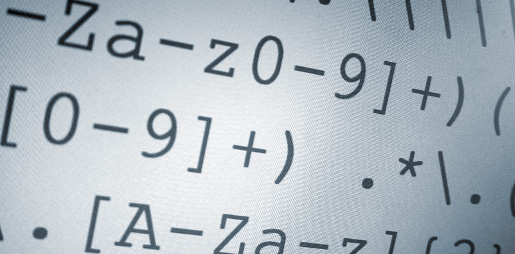
ณัฐธิดา หมวดเพ็ชร [ 30 มิถุนายน 2558 ]
Regular Expression
Regular Expression คือ การกำหนดรูปแบบอักขระ เพื่อใช้ในการค้นหาค่าในรูปแบบของ String โดย Regular Expression มีพื้นฐานมาจากทฤษฎีทางคณิตศาสตร์ที่ใช้ในการเปรียบเทียบข้อความที่ต้องการค้นหากับรูปแบบที่กำหนดว่ามีความสอดคล้องกันหรือไม่
รูปแบบอักขระของ Regular Expression มาจากการผสมอักขระพื้นฐานหลายตัวเข้าด้วยกัน เช่น /abc/ หรือจากการผสมอักขระพื้นฐานกับอักขระพิเศษ เช่น /ab*c/ หรือ/Chapter (\d+)\.\d*/ ที่ใช้เครื่องหมายวงเล็บเป็นหน่วยความจำ โดยข้อความที่ตรงกับรูปแบบอักขระในวงเล็บนี้จะถูกจดจำไว้เพื่อเรียกใช้ในภายหลัง
มาดูสัญลักษณ์ของ Regular Expression ที่ใช้กันบ่อยๆดีกว่า
- ^ แทนความหมายว่า “ขึ้นต้นด้วย” เป็นจุดเริ่มของข้อความ
- $ แทนความหมายว่า “ลงท้ายด้วย” เป็นจุดสิ้นสุดของข้อความ
- . แทนตัวอักษรใด ๆ หนึ่งตัวยกเว้น NULL และแทนตัวขึ้นบรรทัดใหม่
- | ใช้เป็นตัวคั่นเพื่อแสดงตัวเลือก
- ? แทนการเกิดขึ้น 0 หรือ 1 ครั้ง
- + แทนการเกิดขึ้น1 ครั้งเป็นต้นไป
- * แทนการเกิดขึ้น 0 ครั้งขึ้นไป
- \ เป็นเครื่องหมาย Backslash ตรงตัวหรือทำให้ตัวอักษรซึ่งเป็น Operator เช่นเครื่องหมายคูณ, หาร, บวก และลบ กลายเป็นตัวอักษรธรรมดาตัวหนึ่ง เช่น \* จะหมายถึง ตัวดอกจันหนึ่งตัว ไม่ใช่เครื่องหมายคูณเป็นต้น
- ( ) เครื่องหมายกลุ่ม สัญญลักษณ์ทั้งหลายในวงเล็บนี้จะถือเป็นหนึ่งตัว
- [ ] ในเครื่องหมายนี้จะเป็นลิสต์ของตัวอักษร ซึ่งตัวใดตัวหนึ่งในลิสต์สามารถจับคู่ได้กับใน source_string ถ้าต้องการให้เป็นตรงกันข้ามคือต้องการ source_string ที่ไม่มีในลิสต์จะต้องใส่ ^ เข้าไป เช่น ^[a-zA-Z] ห้ามตัวอักษรไม่ว่าตัวเล็กหรือใหญ่
- [. .] แสดงตัวอักษรหนึ่งตัว ซึ่งอาจจะประกอบด้วยอักขระมากกว่าหนึ่งตัว
- i เป็นการจับคู่ตามรูปแบบ โดยไม่สนใจเรื่องตัวอักษรใหญ่หรือเล็ก (Case Insensitive)
- c เป็นการจับคู่ตามรูปแบบ โดยจะสนใจเรื่องตัวอักษรใหญ่หรือเล็ก (Case Insensitive)
การสร้าง Regular Expression มีอยู่ด้วยกัน 2 แบบ
1. การสร้างด้วยตัวข้อมูลแบบ regular expression
![]()
วิธีนี้จะสร้าง regular expression ในทันทีที่เสร็จสิ้นการโหลดสคริปต์ จะให้ประสิทธิภาพที่ดีกว่า ถ้าใช้กับ regular expression ที่ไม่มีการเปลี่ยนแปลงใดๆอีก
2. การเรียกใช้ฟังก์ชัน constructor ของอ็อบเจกต์ RegExp
![]()
วิธีนี้จะสร้าง regular expression ในขณะที่สคริปต์ทำงาน ควรใช้วิธีนี้เมื่อรู้ว่ารูปแบบอักขระของ regular expression อาจมีการเปลี่ยนแปลงได้ หรือใช้ในกรณีที่ไม่ได้กำหนดรูปแบบไว้ในตอนแรก แต่ได้มาในภายหลัง เช่น จากการป้อนข้อมูลของผู้ใช้
ปัญหาที่อาจจะพบได้เมื่อเลือกใช้วิธีที่ 1
เมื่อเราต้องการค้นหาคำที่เราต้องการ /#{name}/i แล้วเราเกิดพิมพ์ผิด เช่น ต้องการจะค้นหา “แมว” แต่พิมพ์ผิดเป็น “(แมว” วิธีนี้อาจทำให้เกิดข้อผิดพลาดขึ้นได้ เพราะโปรแกรมมองว่า “(” เป็นสัญลักษณ์ตัวหนึ่งของ regular expression ตัวหนึ่ง
แต่วิธีที่ 2 อาจแก้ปัญหาของวิธีที่ 1 ได้
โดยเราจะใช้ฟังก์ชัน constructor ของอ็อบเจกต์ RegExp ดังนี้
Regexp.new(Regexp.escape(name), Regexp::IGNORECASE)
( แก้ไขกรณีข้องต้น โดยการใช้ IGNORECASE ) เพียงเท่านี้ก็ทำให้ไม่เกิดข้อผิดพลาดในการค้นหาอีก
ศึกษาข้อมูลเพิ่มเติมได้ที่ : http://ruby-doc.org/core-2.2.0/Regexp.html